Variance is the mean of the squared deviations from the mean.
Instead of finding absolute deviation where we ignored negative signs obtained by subtracting mean from values, we square the difference from the mean. If we had deviation d from the mean, we get another column for d2.
Consider the following set of data:
42, 45, 39, 52, 48, 47, 50, 43, 36, 37
The mean for the data is
42 + 45 + 39 + 52 + 48 + 47 + 50 + 44 +
36 + 37 =440
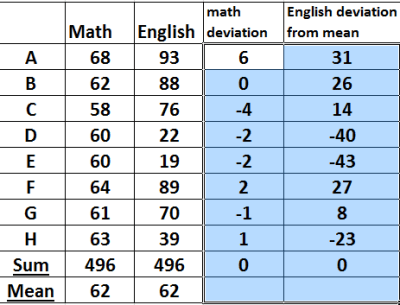
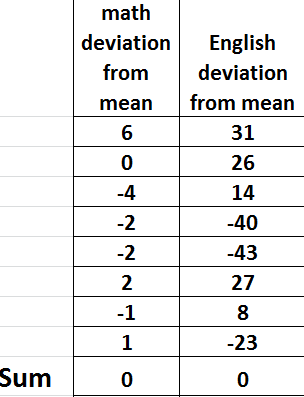
The table below shows deviation from the mean of data representing some marks in a math test.

from the table above, the sum of d2 is 268. That is Σd2 = 268.00
the variance, sometimes written as σ2 is given as Σd2 divided by total frequency N. That is;

In the example above:
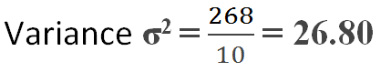
Standard deviation σ
It is also known as the root mean square deviation and is obtained by getting the square root of the variance. In the example above, The standard deviation, sometimes abbreviated as s.d will be given by:

Standard Deviation For a grouped data
standard deviation is useful for a large data.
consider the table below that contains marks distribution for some 40 students.
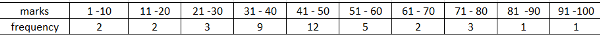
We first calculate the mean for the data using the methods of getting mean for the grouped data.
Here i use the assumed mean of 5.5. I choose this value because it has little value of midpoint and frequency, hence not likely to loose a lot of accuracy when it is reduced to zero
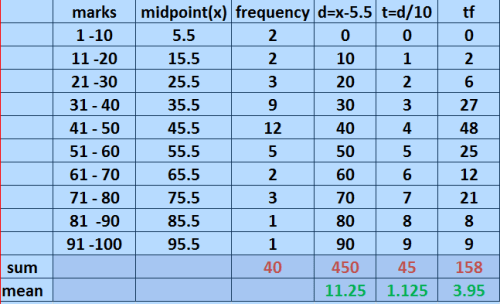
Recall:

From the table above:
∑ft/ ∑f = 3.95
and (∑ft/ ∑f) x 10= 39.5
hence (∑fd/ ∑f) = 39.5
Mean is therefore 39.5 + 5.5 = 45
Now that i have the mean, i will make a table that contains deviations from the mean and the squared deviation from the mean as shown.
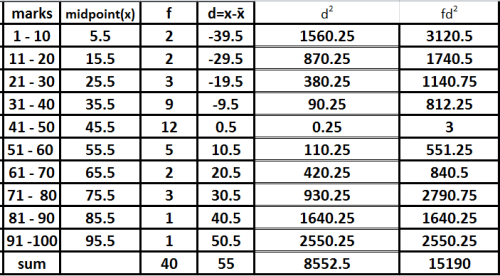
The we will proceed to calculate the variance and get it’s squareroot to get the standard deviation.
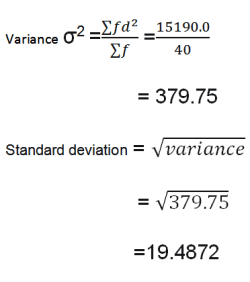
Related Topics
- Introduction to statistics
- Measures of dispersion
- Grouped and ungrouped data
- bar graphs
- Line graphs
- Frequency polygon
- Histograms
- pie charts
- Measures of Central tendency
- Mean for grouped data
- Working with the assumed mean
- Quartiles, Deciles and percentiles
- Measures of dispersion
- Variance